1. Introduction
Digital Talking Books (DTBs) are the digital counterpart of talking books, which have been available for many years to print-disabled readers. Talking books have been offered on analogue media, such as audiocassettes, providing human-speech recordings of a wide array of print material. However, analogue media are limited in several aspects. DTBs overcome most of those limitations:
- Linear presentation of audio narrations - DTBs allow the reader to move around in the book as freely as in a printed book.
- Users cannot place bookmarks or highlight material - DTBs offer these interaction capabilities.
- No access to the spelling of words - DTBs store full text, synchronized with the audio presentation, allowing readers to locate specific words and hear them spelled.
- Only one version of the work is presented - For example, footnotes are either read when referenced or grouped at a location out of the flow of the text. A DTB allows easily skipping or reading the footnotes when desired.
These and other limitations can be overcome because DTBs can include not just the audio recording of the work, but the full text content and images as well. Because the text is synchronized with the audio, a DTB offers multiple sensory inputs to readers. This can be beneficial to learning-disabled readers and to other target audiences such as blind, visually impaired, physically handicapped and otherwise print-disabled readers (Moreno and Mayer 2000). For these audiences the DTB offers a significantly enhanced reading experience. For other audiences, balancing DTB modes and media can be explored to overcome the cognitive limitations of human perception and attention (Gazzaniga et al 1998).
Over the last years several DTB players have been developed. However, a heuristic evaluation of some of those players (Duarte and Carriço 2005) found several usability and accessibility flaws. The evaluation results support the introduction of multiple modalities and adaptive capabilities, not only to solve the usability and accessibility problems, but also to improve the reading experience and help in exploring the richer contents a DTB offers.
The development of an adaptive multimodal application is a complex task, and it would greatly benefit from the support of some framework, conceptual model, methodology or tool. The development process presented in this article is based on FAME, a Framework for Adaptive Multimodal Environments. FAME was selected over other frameworks, due to the ability to integrate multimodal input and output with adaptation capabilities, which is very relevant given the characteristics of the application to develop. Other frameworks dealing with adaptation do not target multimodal environments, focusing instead in multi-device situations, and other frameworks targeting multimodal applications do not consider adaptation.
The remainder of the article will first detail the expected features of a DTB player. Next, FAME is presented. This is followed by a description of the adaptive multimodal DTB player development process. Before presenting the conclusions, the characteristics of existing frameworks related to FAME are described in the Related Work section.
2. Digital Talking Books
DTB developments over the last years lead to the appearance of several different specifications, with the Daisy Consortium being responsible for the major work done in the area, and the publication of several standards (DAISY 2.0 in 1998, DAISY 2.01 in 1999 and DAISY 2.02 in 2001). Finally, in 2002, with cooperation from the Daisy Consortium, the National Information Standards Organization (NISO) published the standard ANSI/NISO z39.86-2002, which has been revised in 2005, leading to the current standard ANSI/NISO Z39.86-2005. The standard focuses on the files, their structure and content, needed to produce DTBs. However, specifications for playback devices are absent from the standard. An auxiliary document, the Digital Talking Book Player Features List, created during the standard's development, describes the main features that playback devices should possess, but it is not normative and does not present specific implementation solutions.
According to the Digital Talking Book Player Features List, the NISO DTB committee recommends that three types of playback devices be developed: first, a basic DTB player, defined as a portable unit capable of playing digital audio recordings, for use mostly by less sophisticated talking book readers who wish to read primarily in a linear fashion. Second, an advanced DTB player, also portable, but designed for use by students, professionals and others who wish to access documents randomly, set bookmarks, etc. Finally, a computer based DTB player, consisting only of software and being the most complete and sophisticated of the three. For this final configuration, the Digital Talking Book Player Features List defines as essential a set of features, including the following:
- No need to use a visual display to operate device
- Variable playback speed
- Document accessible at fine level of detail
- Usable table of contents
- Easy skips (moving sequentially through the elements)
- Ability to move directly to a specific target
- Ability to manage notes
- Reading of notes
- Setting and labeling bookmarks
- Automatic bookmark at stop
- Ability to add information (highlighting and notes)
- Spell words
- Fast forward and fast reverse
- Human and electronic speech must be available
- Presentation of visual elements in alternative formats (speech)
The Daisy Consortium publishes and maintains a list of Playback Tools. A Consortium was presented by Duarte and Carriço (2005). heuristic evaluation of eight of the software players referenced by the Daisy The evaluation finds several usability and accessibility problems, either due to poor feature implementation, or due to the lack of some of the required features. The evaluation considered aspects regarding navigation, personalization, implementation of bookmarks and annotations, and the use of different modalities. The flaws identified include:
- Lack of awareness of current navigation element
- Lack of support to move to specific targets
- Lack of awareness to the presence of annotations
- Impossibility to use the player without a visual display for all but the simpler tasks
- No alternative presentations of visual elements
The evaluation concludes that, although the players can be used without much difficulty by non visually impaired users, the same cannot be said for visually impaired ones, which are their main target audiences. The authors suggest the use of more modalities, especially for the input side, and the introduction of adaptive capabilities to help users better explore the possibilities of the interface and even the book's contents. These additions, if implemented correctly, would certainly improve the readers' awareness of the different elements, and increase the accessibility of the player by allowing its use without visual elements, and by making available alternative presentations.
The development of an adaptive multimodal DTB player, that would help overcome these limitations, is a complex process. In the following section, the FAME framework, used to guide the development of the player, is introduced.
3. FAME - Framework for Adaptive Multimodal Environments
FAME is a model-based Framework for Adaptive Multimodal Environments. It aims at integrating characteristics from both multimodal and adaptive applications into one reference framework. The adaptation is based on variations of the context of use. The context of use is characterized by three entities, in a way similar to the CAMELEON framework (Calvary et al 2003): User, Platform and Environment.
These three entities are directly related to FAME's three context models: User, Platform & devices and Environment. Each model is supplied by its observers. An observer is a sensing enabled device or process, responsible for acquiring and transmitting information to the context model. This information is then used to update the model state. The three models and possible observers are described in the following paragraphs:
- User model - this model stores relevant information about the user. The information stored will depend on the application domain, but it should be enough to characterize the user's perceptual, cognitive and action capacities. Applications built with accessibility concerns should capture the degree of user impairments in this model. This model can also store user preferences. Observers for this model may range from direct questions to the user, to inferences based on the user behavior. Other observers may include physical measures, like heartbeat or blood pressure monitoring to determine anxiety states, for instance.
- Platform & devices model - this model stores information about interaction devices available, characteristics of the execution platform and application specific events. The knowledge about the interaction devices and the execution platform is relevant to the choice of what modalities to use for input and output and the amount of information to present to users. This information may include memory size, network bandwidth, screen dimensions and resolution, and the availability of hardware and software artifacts, like microphones and speech recognizers, for example. Unlike the CAMELEON framework, this model also stores application specific events that may impact the way the user interacts with the application. These events may have their origin on a regular application execution pathway, or be triggered by some user action. They result in an application state change that may impact the user interaction, and benefit from some form of adaptation. For example, the appearance of a new window could trigger a mechanism for rearranging the visible windows, thus adapting the visual presentation. Observers for this kind of events should be defined during the analysis of the application and monitor all the occurrences of the events deemed to have such an impact. Observers for the interaction devices and execution platform characteristics should monitor changes in their settings, as well as the presence or absence of the devices.
- Environment model - this model stores data about the characteristics of the environment surrounding the execution platform. For example, ambient noise should be considered for applications where speech recognition or audio outputs are used. Lighting conditions are relevant for applications using vision-based tracking (Crowley et al 2000). Observers for this model are mainly sensors capable of capturing the environmental condition or conditions relevant to good application performance.
The information stored in the models is used to define contexts of use. The adaptation engine should monitor the context of use and identify changes in the context. A change in the context occurs when one attribute or a combination of different attributes of the models change state. Two or more states are defined for each model's attribute based on the attribute in question, its data type and the application domain. Whenever a change of context is detected the adaptation engine fires one or more adaptation rules in order to try and preserve the usability and accessibility features of the application (Calvary et al 2002).
Figure 1 presents an overview of FAME's architecture. The three models described above can be seen inside the adaptation module. A fourth model, named Interaction model is also present inside the adaptation module. This model describes the components available for presentation and interaction, and the ways in which they can be combined to generate presentations. Each component is described by one or more templates. These component templates define how a component is to be presented in the several modalities available. For instance, for presenting the text of a book's page, three component templates can be defined: one for presenting on a screen, defining font characteristics; other for presenting with a speech synthesizer, defining the voice characteristics; and another for presenting on a Braille device. Besides the component templates, the Interaction model also stores composite templates. These are responsible for defining relationships between components in order to be possible to group components into a presentation. Composite templates can be a combination of two or more component or composite templates. The combination may be between components of different modalities. The component and composite templates create an Abstract User Interface defining the relations between the different elements of the interface. This interface is then instantiated in run-time, when the interface constraints (like screen resolution, for instance) are known, to create a Concrete User Interface.

Figure 1. FAME's architecture.
Another feature of the framework is the responsibility of the adaptation module in shaping the multimodal fusion and fission components. The adaptation module can influence the behavior of both operations by determining the importance of each modality and the patterns of integration in the fusion and fission processes. The multimodal fusion component is responsible for determining the intended user's actions from the information gathered over the different input modalities available. The choice of the weights can be determined either from perceived user behavior or environmental conditions (in a noisy environment the weight associated with the speech recognition module can be lowered). The user model could also be used to influence the multimodal fusion operation, as it has been shown that different individuals have different patterns of multimodal integration (Oviatt 2003).
The multimodal fission component translates the system actions, into one or more outputs in different modalities. The adaptation module responsibility of adapting the presentation's content and layout is directly related with the multimodal fission processing, in determining ways in which the content should be transmitted to the user. Also, the output layout is decided, taking into account factors such as the output devices' capabilities and the users' preferences, characteristics and knowledge.
The only component of FAME's architecture not yet described is the adaptation engine. For the representation of the adaptation rules, FAME introduces the concept of Behavioral Matrix.
3.1 Behavioral Matrix
A behavioral matrix describes the adaptation rules, past interactions, and cognitive, sensorial and other information relevant to the rule's application. One behavioral matrix should be designed for each of the application's adaptable component. The matrix dimensions reflect the behavioral dimensions governing the interaction with the specific component. For instance, one of the dimensions can represent the output modality or combination of modalities used by the component to transmit information to the user. Other dimensions can describe how the information should be presented, what information to present and when to present it.
Each of the matrix's cells holds a tuple with up to three elements. The first element of the tuple defines the rules currently in use. Consider the two-dimensional matrix presented in Figure 2 relating the output modality selection behavior of an application with the visual impairment level of its users. This matrix defines three rules. Depending on the visual impairment level of the user, a different combination of output modalities is selected. For each cell of the behavioral matrix, if the first element of the tuple is set, the rule defined by the behaviors associated with each of the matrix dimensions is currently in use, and may be triggered whenever a change of context is detected.

Figure 2. An example two-dimensional matrix with only one element of each tuple.
The second element of the tuple counts the number of times the rule has been activated by the user's direct intervention. This value stores information about the user's preferred behavior, laying the ground for adaptation of the behavioral matrix itself.
The third element defines a condition used to activate the corresponding rule. This condition, using logical and comparison operators, relates the second value of two or more tuples. The tuples are referenced by their position in the matrix. If the condition is found true the corresponding rule becomes active. If the condition associated to an active rule is found false, then the corresponding rule becomes inactive. Consider now the matrix presented in Figure 3, with all the elements of each tuple. This matrix relates the complexity level of instructions provided to the user, with the modality combinations in which they are provided.

Figure 3. An example two-dimensional matrix with all elements of each tuple.
The tuple on the first column of the first row defines an active rule, which has never been directly activated by user intervention. The same can be said for all the rules, due to the fact that all have the second element of the corresponding tuple still at zero. The third and final element of the tuple specifies that the rule should become active whenever its activation count is superior to the activation count of the tuple in the first column, second row. This will make the interface follow the exhibited user behavior. For instance, if still using only visual output, the user would change the instructions complexity to simple, the activation count on cell (1,2) would rise to one. This would immediately activate the rule of cell (1,2) and deactivate rule of cell (1,1), because its condition would have became false.
Thanks to this last value of the tuple, the behavioral matrix allows for dynamic selection of adaptation rules in response to changes of the context of use.
Having described FAME, in the next section the development of an adaptive multimodal DTB player based on the FAME framework is presented.
4. Development of an Adaptive Multimodal DTB Player
This section reports the development of a software DTB player for a PC-based platform. The following input modalities are available on the platform: keyboard, pointing device (mouse or touchpad) and speech recognition. The output modalities available are: visual for presenting text and images, and audio for playback and speech synthesis.
The development process starts with the selection of the attributes for the User, Platform & devices, and Environment models. User attributes include the visual impairment level and preferences pertaining to the presentation of annotations and images. Observers for the preferences detect the users' behavior whenever a situation concerning annotation or image presentation arises. The users' visual impairment level is declared before application start. The only environment attribute used is the ambient noise level. An observer for this model samples at regular intervals the ambient noise to detect changes in the noise level. The Platform & devices model stores attributes concerning the characteristics of the execution platform and the interaction devices available. These include flags to mark the presence or absence of a microphone, and of speech synthesis and recognition modules. The language model of these modules is also stored. Another attribute is the screen resolution. Events originated by the user include every action that directly influences the playback and presentation of the book, like changing the narration speed, or altering the placement of visual elements. Actions that were not considered are the ones such as opening or closing a book. Application originated events that may initiate adaptation include all events that are part of the author defined presentation (for instance, the presentation of images may trigger the rearrangement of the visual elements of the interface) and events signaling the presence of user created markings (for example, signaling the presence of an annotation).
To continue the development, the adaptable components and their corresponding behavioral dimensions must be identified (Duarte and Carriço 2004). The adaptable components were mapped to the several elements of a DTB: Book content, Table of contents, Annotations and other Miscellaneous content (includes tables, images, side notes, etc.). For the Miscellaneous component, the following four behavior dimensions and corresponding values were identified:
- Action - show (presents the content), alert (alerts to the presence of content without displaying it) and ignore (does not take any action).
- Visibility - always (the component is always displayed) and hide (the component is hidden after the content has been presented).
- Modality - visual (the content is displayed using graphical output), audio (the content is presented using sounds or speech) and both (both visual and audio modalities are used to display the component's content).
- Reading - pause (during the content's presentation the narration of the book's main content is paused) and continue (during the content's presentation the narration of the book's main content goes on).
For the Annotations component, the four previous behavior dimensions were replicated and two new dimensions added:
- Reaction - advance (when the user consults the annotation, the narration jumps to its creation point) and remain (no jump is associated with an annotation consultation).
- Content - list (the default content of the annotations component is the list of created annotations, with the selected annotation being shown only during the presentation of the annotation's text) and item (the annotation's text remains the content of the annotations component until the user requires the annotations list).
The Table of contents component retains three of the dimensions previously introduced (modality, visibility and reading) and introduces a new dimension:
- Presentation - collapse (the entries of the Table of contents are presented collapsed and the user is responsible for navigating to the pretended entry), current (the nodes of the Table of contents leading to the current section of text are presented expanded) and expand (all the nodes of the Table of contents are presented expanded).
Finally, the Book content component repeats the modality dimension and introduces six new ones:
- Synchronization - word, sentence and paragraph (determines the granularity of the visual highlighting accompanying the audio narration of the text).
- Speed - slow, normal and fast (represents the speed of the audio narration).
- Marking presentation - off (no marking is exhibited to the user), miscellaneous (a marking is exhibited in all the main book content parts associated with miscellaneous content, like images, tables, or side notes), own notes (a marking is exhibited in all the main book content parts that have been annotated by the reader), other notes (a marking is exhibited in all the main book content parts that have been annotated by other readers), all notes (a marking is exhibited in all the main book content parts that have been annotated by any reader) and all (every mark is exhibited).
- Marking presentation modality - takes the same values as the modality behavior dimension.
- Reading path - normal (the narration follows the author's defined path), own notes (the reading path is made up of only the book parts that have been annotated by the reader), other notes (the reading path is made up of only the book parts that have been annotated by other readers) and all notes (the reading path is made up of only the book parts that have been annotated).
- Reading path content - original (the content presented when on an alternative reading path is the original content) and note (the content presented when on alternative reading paths is the notes entered by the users.
The development process continues with the definition of the component and composite templates of the Interaction model. For each adaptable component at least one component template is defined for each of the output modalities. For the Miscellaneous component more than one component template for each output modality is defined, as this component is used to present information with different structure, like an image and a side note. For example, the component template for image presentation in the Miscellaneous component specifies that, when visually presenting an image, the image title is presented above the image, and the image caption is presented bellow the image. When presenting the image using speech, another template specifies that the title is followed by the caption and a previously recorded image description. Both these templates can be in use simultaneously when audio and visual output modalities are employed. Another example is the Book content template, which defines how the synchronization is presented visually, margin sizes, fonts and other presentation details. The template for audio presentation might specify narration speed and the narrator model to use in case of outputting speech synthesized voice.
After defining the component templates, the composite templates follow. These templates are responsible for deciding the relative placement, sequencing and other relations between each of the component templates that are present in the Abstract User Interface. The decision is based on the number and type of components being presented. Besides this, user preferences can also be used to guide the decision process. When preparing the visual part of the Abstract User Interface the composite templates define size and placement of each component relative to the others. For the audio part of the Abstract User Interface, and because of the one-dimensional nature of audio, the composite templates define the sequence of presentation of the components. The Abstract User Interface is determined every time the application detects a change in context. Whenever one Abstract User Interface is determined it can be instantiated by the application, to build the Concrete User Interface, which the user sees, listens to, and interacts with.
The development process follows with the definition of the multimodal fusion and fission operations. In the DTB player, multimodal fusion will be used to combine speech input with the input from the pointing device whenever the context determines it. The fusion is used when a generic command to show or hide is recognized by the speech recognizer. This may happen in three different scenarios:
- The user is being alerted to the presence of an image or an annotation. A generic show command will determine the component that will be shown based on this alert.
- The previous situation is not occurring and an image or annotation has been shown or hid by the user or the system recently. A generic show or hide command will determine the affected command based on that event.
- The first situation is not occurring, and no image or annotation has been shown or hid recently. A generic show or hide command is fused with the pointer position to determine what component is affected by the command.
The multimodal fission is mostly controlled by the choice of composite templates. The instantiation of the Abstract User Interface into a Concrete User Interface determines the necessary fission operations. For instance, the fission operation is responsible for guarantying synchronization between the visual presentation and the audio narration of the Book content component. Other situation where the fission operation may be used is when alerting the user to the presence of an image or an annotation. In such cases, more than one modality can be used to alert the user, with the fission operation deciding upon the most appropriate course of action.
Finally, the adaptation rules have to be defined. This involves building a behavioral matrix for each of the four previously identified adaptable components. The dimensions of the behavioral matrix were also identified previously. The application designer's role at this point is filling the tuples. Decisions must be made over which rules will start active, and how do context changes impact the rule selection. In the following paragraphs examples of the rules encoded in the behavioral matrices of all the adaptable components will be given. The full matrices cannot be visually presented, but relations between two of the matrix's dimensions are presented.
Figure 4 shows the relation between two of the dimensions of the Miscellaneous component behavioral matrix. According to the rules encoded in the matrix, if the content is displayed using audio output then the main content narration pauses. The main content narration also pauses when both audio and visual output are used. In this fashion the overlap of two different audio tracks is prevented. This behavior may change if the user behavior reflects different preferences.

Figure 4. Two of the dimensions of the behavioral matrix for the Miscellaneous component.
Figure 5 shows the relation between two dimensions of the Annotations component behavioral matrix. This shows that if the preferred user behavior is to have the annotations presented whenever they are reached during the narration, they should be presented using visual output. If, on the other hand, the user prefers to be alerted to the presence of an annotation, but not have the annotation shown immediately, then both output modalities should be used to warn the user. This application behavior is not altered in run-time.

Figure 5. Two of the dimensions of the behavioral matrix for the Annotations component.
The dimensions of the Table of contents behavioral matrix presented in Figure 6 show that when the output modality for the Table of contents component is visual then the Table of contents should be presented expanded. When audio is used as output modality then only the nodes leading to the node of the section currently being read are to be presented, in order to avoid having the speech component reading or synthesizing all the entries of the Table of contents.

Figure 6. Two of the dimensions of the behavioral matrix for the Table of contents component.
The behavioral matrix for the Book content component, presented in Figure 7, relates the synchronization and speed dimensions. The synchronization unit grows (from word, to sentence, to paragraph) according to the reading speed (from slow, to normal to fast). The value for the dimension reading speed is determined by an observer that detects user initiated alterations to the playback speed, and translates the playback speed to the attribute reading speed according to two threshold values: one for the transition from slow to normal, and the other for the transition from normal to fast.

Figure 7. Two of the dimensions of the behavioral matrix for the Book content component.
Having provided a global overview of the development process of the adaptive DTB player, the next section presents some of its features and functionalities.
4.1 Features of the Adaptive Multimodal DTB Player
As identified in the previous section the DTB player is composed of four main components: the Book content, the Table of contents, the Annotations and the Miscellaneous content. These components have representations in two modalities: visual and audio. Figure 8 shows an instance of a Concrete User Interface, with the windows corresponding to all the components visible. Two ways of raising the reader's awareness by situating him in the book can be perceived in Figure 8. First, the visual synchronization marker highlights the word being narrated. Second, the current section or chapter number is also highlighted in the Table of contents. Another awareness raising feature of the player is directed at annotations and images. Annotation awareness is raised in two distinct ways: the show/hide annotations button flashes every time the narration reaches a point in the text that has been annotated and the annotations window is not being displayed. If the annotations window is displayed, the text that has been annotated is highlighted in the Book content window in a different manner from the synchronization highlight. The image presence awareness is raised in a similar fashion, but only the flashing button applies.
http://journals.tdl.org/jodi/article/downloadFile/236/2086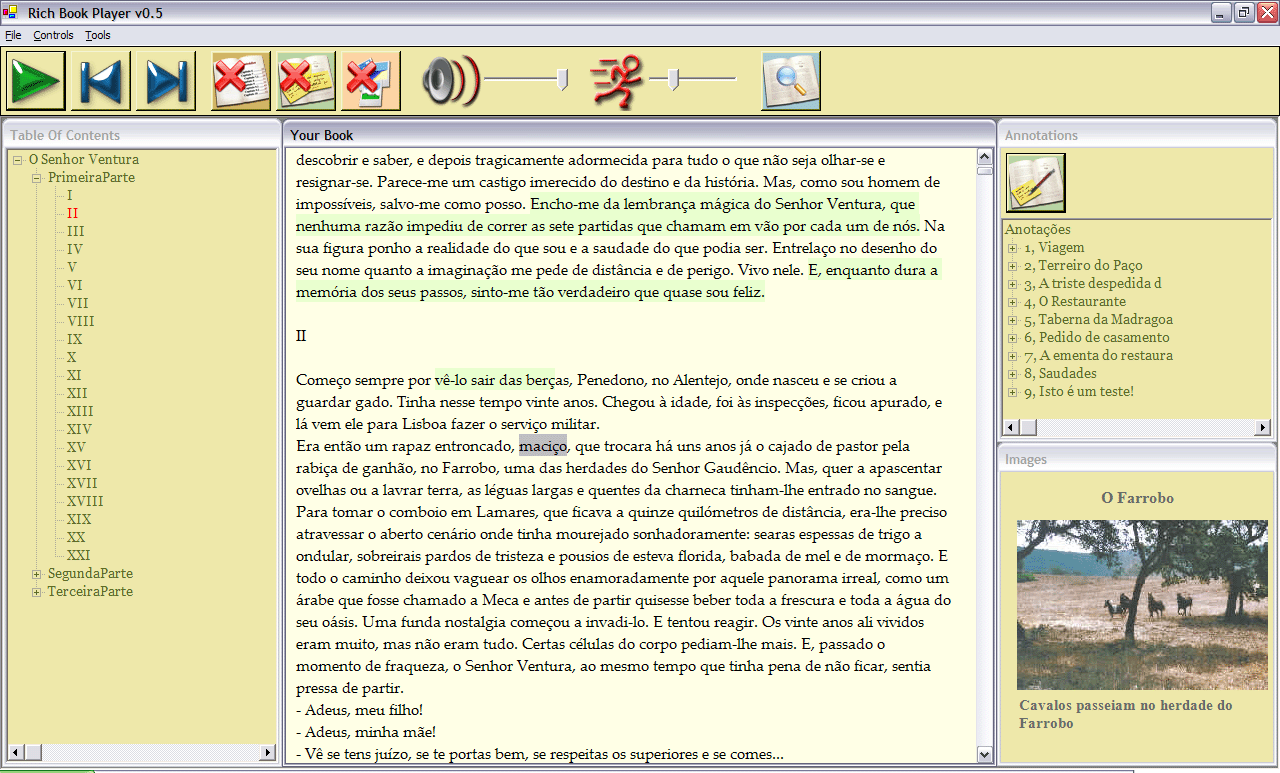
Figure 8. The DTB player visual interface, presenting
main content, table of contents, list of annotations and an image.
One of the features of the player is the possibility to customize and adapt the visual presentation of, not only the size, fonts and colors, but also the disposition of the presented components. If the reader is not satisfied with the configuration she can move any component to a new position, and the player will rearrange all the windows' positions automatically. Figure 9 shows the interface after the user moved the image window to the bottom left. As can be seen, the height of the table of contents and annotation windows was changed in response to the user order. The user may also choose to hide any of the visible windows. Figure 10 shows the interface after the user hid the annotations window. The image window reclaimed the space left unused by the vanishing window. The space was occupied by the image window instead of the main content window because the adaptive visual presentation always tries to minimize the movements of the main content window, in order to minimize causing distractions to the user. This adaptive behavior can also be triggered by an automatic presentation of a previously hidden component, which can happen, for example, when the narration reaches a point where an image or a table should be presented.

Figure 9. The visual interface adapts itself after the
user moved the image window.
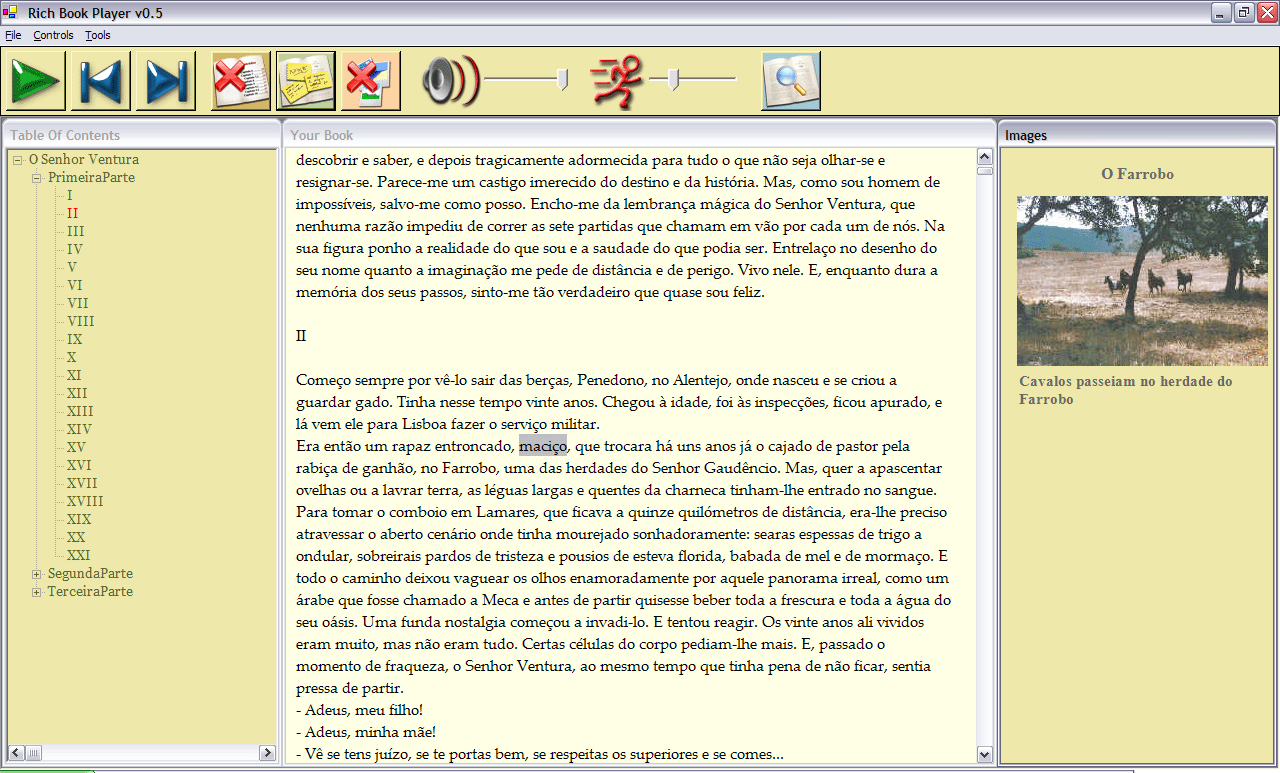
Figure 10. The visual interface adapts again after the user
hid the annotations window.
Other adaptive behaviors are exhibited by the player. The synchronization unit between highlighted text and narrated audio can be automatically set by the adaptation module, in response to user actions. A possible triggering action is the selection of a new narration speed. The increase in narration speed will move the highlight from word to word faster. A speed will be reached where it will be perceptually difficult to accompany the highlighted word. Recalling the behavioral matrix for the book content presented earlier (Figure 7), the adaptation engine will try to diminish this effect by increasing the synchronization unit as the speed rises. The established path is to move from word synchronization, to sentence synchronization, to paragraph synchronization.
Other event triggering the same adaptation is a rapid succession of commands to advance (or go back) to the next (or previous) navigation unit. This will result in an increase of the navigation unit, as the system perceives the intended user action of quickly navigating forward. An increased unit will allow for the same intended result with fewer commands issued. Other events adapting the navigation unit are free jumps in the book, resulting from searches performed on the content. The navigation unit is chosen taking into account the distance between the starting and ending points of the jump. The reasoning behind this adaptation is that the greater the distance, the bigger the difference in context. If the jump is to a close location, or one that has been read recently, then the navigation unit is smaller: word or sentence. If the jump is to a far location, or one that hasn't been read, then the navigation unit is bigger: paragraph or section.
The interface behavior is also adapted in response to the user's behavior relating to the presentation of annotations and miscellaneous content. The default initial behavior is to alert the user to the presence of such content, without displaying it. If the user repeatedly ignores such alerts then the interface's behavior is changed in order to stop alerting the user, effectively ignoring the presence of such content. This is the "ignore" value of the action dimension of the Annotation and Miscellaneous components' behavioral matrices. If the user behavior is to acknowledge the alerts and consult the annotations or the miscellaneous content, then the interface's default behavior becomes presenting the content without alerting the user. This is the "show" value for the action dimension of the referenced matrices.
Other example of adaptive behavior is the selection of the rule detailing the behavior of the player when presenting annotations or miscellaneous content (Figure 4 presents these dimensions for the Miscellaneous component behavioral matrix). The default behavior of pausing the book's narration when these components are presented aurally, or continuing the book's narration when not, can be adapted according to the user behavior.
Another feature of the player aims particularly the reading of technical and reference works. This feature concerns text re-reading of highlighted parts. When reading technical works, the reader usually underlines relevant passages of the text, sometimes using different colors or marking styles, in order to convey different relevance levels or categories. In a later re-reading the reader attention is usually focused on those passages. The player supports this functionality by allowing the reader to annotate the text and categorize the annotations. From these categorizations several behaviors can be devised for further readings of the same book: reading of only the annotated material; reading material of only specific categories; association of different reading speeds to different categories. A possibility opened up by this feature is the user creation and reading of text trails that may constitute content perspectives, sub stories, argumentation paths, etc.
The most important limitations observed in the heuristic evaluation mentioned before, are now recalled, and the features of the developed DTB player that overcome the limitations are referred:
- Lack of awareness of current navigation element - Navigation can be done using speech commands (next word, next paragraph, etc.) that are completely unambiguous. Navigation using interface buttons or possibly ambiguous speech commands (next and previous) always refer to the displayed synchronization unit. In this way, the user is always aware to the navigation element used.
- Lack of support to move to specific targets - The user can select with the pointer device any point in the text to move to. Besides this, the Table of contents and the Annotations list can also be used for navigation operations.
- Lack of awareness to the presence of annotations - The player warns the user to the presence of annotations (and images) by flashing the show/hide annotations button. Besides the button flashing it is also possible to have sound cues to alert visually impaired users to the presence of annotations. Annotated text is highlighted in the Book content component, as another way to make the reader aware of annotations.
- Impossibility to use the player without a visual display for all but the simpler tasks and No alternative presentations of visual elements - Being a multimodal player these issues are also solved. Every presentable component has visual and audio output (images have prepared textual descriptions besides the captions). All the interface commands can be issued using the pointer device or speech commands. The only feature not fully supported is the search feature. This is due to the player using a grammar for speech recognition limited to the interface commands. For searching in the book a different grammar would have to be used.
Usability studies conducted meanwhile (Duarte et al 2007) support these findings. Questionnaires concluded that the mechanisms available for raising awareness to the current navigation element, the presence of annotations and the presence of images, were considered usable and efficient by the study participants. The navigation features were also considered usable. Observations, made during several hours of use of the DTB player by different users, confirm the results of the questionnaires. These results demonstrate the successful overcoming of the limitations identified in the first three points above. Regarding the last point, another set of tests (Duarte et al 2006), where the users were asked to interact with the DTB player using only audio channels, proved that all tasks could be achieved without a visual display, although annotation creation raised more difficulties than expected, prompting a revision of the interaction components associated with that task.
From the above discussion it can be seen that a DTB player incorporating multimodal and adaptive capabilities can overcome the limitations identified, and provide features that can make the reading experience more entertaining and productive.
5. Related Work
Multimodal and adaptive interfaces, with their unique characteristics, are still to achieve the same degree of support for application development that standard interfaces have reached. The majority of current approaches either addresses specific technical problems, or is dedicated to specific modalities. The technical problems dealt with include multimodal fusion (Flippo et al 2003, Elting et al 2003), presentation planning (Elting et al 2003, Jacobs et al 2003), content selection (Gotz and Mayer-Patel 2004), multimodal disambiguation (Oviatt 1999), dialogue structures (Blechschmitt and Strödecke 2002) or input management (Dragicevic and Fekete 2004). Platforms that combine specific modalities are in most cases dedicated to speech and gesture (Oviatt et al 2000, Sharma et al 2003). Other combinations include speech and face recognition (Garg et al 2003) or vision and haptics (Harders and Székely 2003). Even though the work done in tackling technical problems is of fundamental importance to the development of adaptive and multimodal interfaces, it is of a very particular nature, and not suited for a more general interface description. The same can be said of specific modality combinations, where some of the contributions do not generalize for other modality combinations, due to nature of the recognition technologies involved.
Still, frameworks exist that adopt a more general approach to the problem of multimodal interface development. The ICARE project (Bouchet et al 2004), a framework for rapid development of multimodal interfaces, shares some concepts with the framework presented here. The ICARE conceptual model includes elementary and modality dependent components as well as composition components for combining modalities. ICARE is valuable for development of multimodal interfaces. However it targets platforms that do not include adaptation capabilities, and thus leaves adaptation related details out of the development process.
Frameworks to support adaptation can also be found. For example, adaptable hypermedia systems have been developed over the last years, leading to the conception of models for adaptive hypermedia, like the AHAM model (DeBra et al 1999). However, these models are usually targeted at platforms with very specific characteristics, with a greater focus on content and link adaptation for presentation purposes, completely ignoring the requirements of multimodal applications. Outside the hypermedia field we can find, for instance, the Unified User Interface (UUI) methodology (Stephanidis and Savidis 2001), which argues for the inclusion of adaptive behavior from the early stages of design. This methodology aims to improve interface accessibility by adapting to the user and context. The UUI framework is based on a unified interface specification and an architecture for implementation of the dialogue patterns identified. Although supporting interface development for multi-device platforms, this methodology does not deal with the specificities of multimodal characteristics.
The framework with the greater similarities to the work presented here is the CAMELEON framework (Balme et al 2004). Like in FAME, the CAMELEON framework uses a triple entity context (User, Platform and Environment). Like in FAME, CAMELEON identifies a set of observers for maintaining the context of use. Like in FAME, the observers feed an adaptation engine that computes the reaction in case of changes in the context of use. The greater difference comes from the outer level that does not appear in CAMELEON as the framework does not specifically addresses multimodal interactive systems, but is more targeted at multi device systems.
6. Conclusions
This article presented FAME, a conceptual framework for the development of adaptive multimodal applications. This framework distinguishes itself by integrating concepts from adaptive systems and multimodal environments into a single architecture. FAME uses a context notion, based on three entities: the User, the Platform and the Environment. The adaptation is triggered by changes in the context of use. The changes can be initiated by user actions, environmental changes and application generated events. The adaptation can have an impact over the multimodal operations of fusion and fission, by altering the weights of each modality and even the integration patterns. FAME introduces the notion of Behavioral Matrix. The Behavioral Matrix is used to represent the adaptation rules, storing information about the active rules, an activation count, and a mechanism for altering the active rules in response to changes in context. Another advantage of the use of the Behavioral Matrix is the reduced complexity when expressing several adaptation rules at the same time.
As a means of proving FAME's feasibility, an adaptive multimodal DTB player was developed. Prior to the development, several limitations of current DTB players were identified. The DTB player, developed according to FAME's architecture and recommendations, has proven that through the use of multimodalities and adaptive features, those limitations can be overcome. The DTB player used three different input modalities (audio, pointing devices and keyboard) and two output modalities (audio and visual). This increased its accessibility, overcoming the problems identified in other players. Also, the interface was designed to increase awareness of what is happening during the narration, overcoming another class of limitations.